
當醫療遇上 AI,算力基礎建設決定一切
在政府推動的「健康台灣深耕計畫」政策框架下,愈來愈多醫療機構開始重視 AI 算力基礎建設的戰略意義。如何在有限的機房空間與預算中,穩健支撐高併發的 AI 推論工作負載,已成為醫院 IT 部門的核心挑戰。
國眾電腦已協助醫療機構建置完整的 AI 算力虛擬化平台,透過超融合架構、異質 GPU 資源池以及軟體定義儲存的整合,讓醫院能靈活因應 AI 工作負載的爆發性需求,並在資源有限的情況下保持高效與穩定。
為什麼 GPU 伺服器架構需要「彈性」?
AI 推論工作負載有一個顯著特性:峰值與離峰的算力需求差距極大。
例如門診影像辨識、語音摘要、臨床決策輔助系統,在早上 8 點到 12 點的請求量,往往是深夜的數十倍。若以峰值需求配置固定資源,將導致大量閒置;若僅依平均值配置,尖峰時段的推論延遲則會嚴重影響臨床效率。
真正的解方並不是「買更多 GPU」,而是建立可彈性調度的 GPU 虛擬化資源池,讓算力能隨需求動態分配,既避免浪費,也確保臨床服務在高峰期依然流暢。
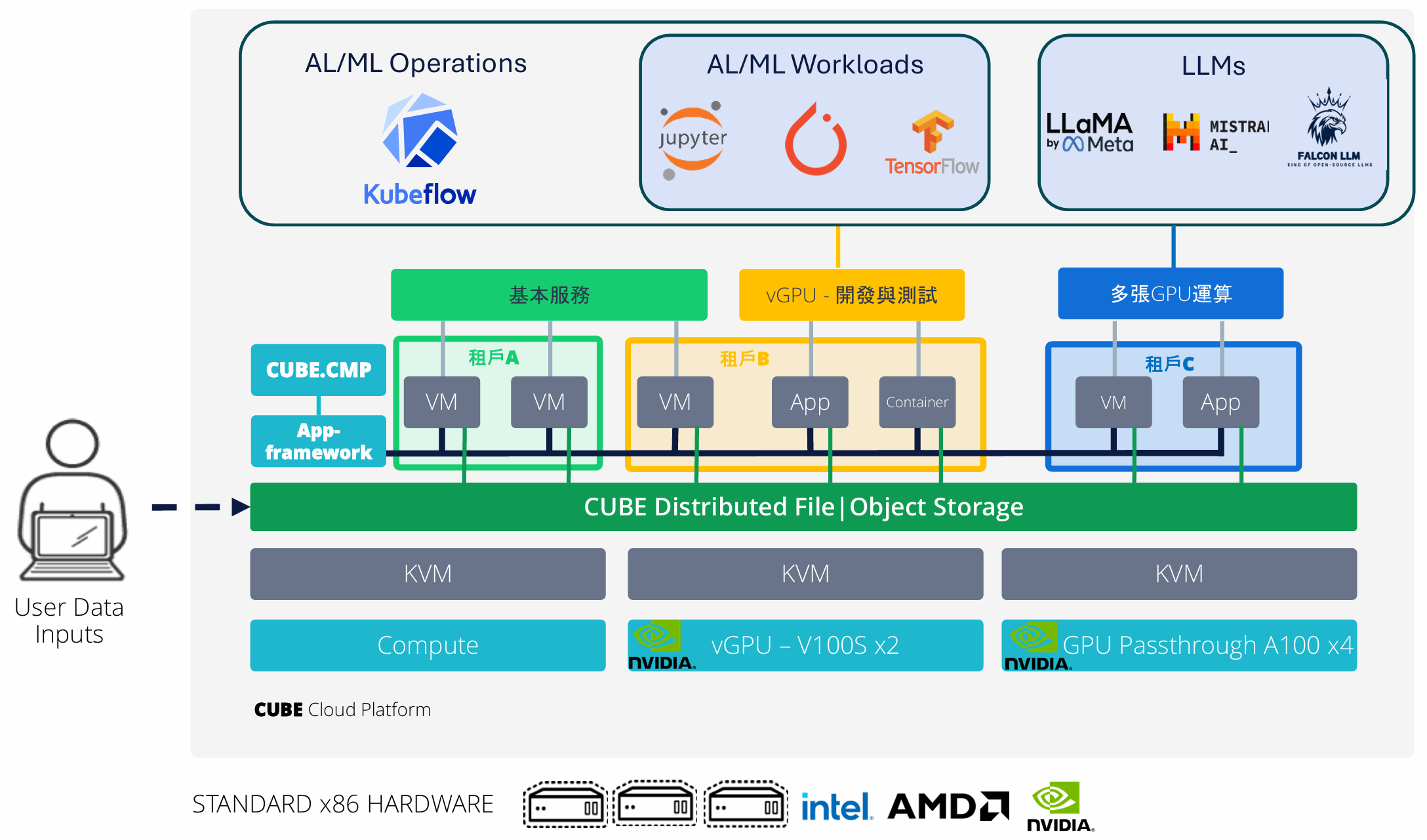
典型部署架構:3 節點異質 GPU HCI
架構概覽
建議採用 Bigstack CubeCOS 超融合雲運算平台,建構 3 節點 HCI 叢集,整合異質 GPU 資源,實現統一排程與叢集高可用性。
以下為一組典型的醫療 AI 算力配置參考,GPU 型號、數量與記憶體規格均可依客戶實際工作負載需求彈性調整:
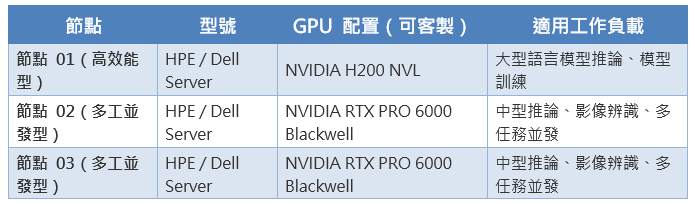
彈性選型說明:GPU 配置並非固定組合。客戶可依預算、工作負載類型與未來擴充計畫,自由選擇 NVIDIA H100、H200、L40S、RTX PRO 系列等不同型號,每節點 GPU 數量亦可按機型上限調整。國眾電腦提供選型諮詢服務,協助客戶找到性價比最佳的組合方案。
核心軟體平台:Bigstack CubeCOS 超融合雲運算平台
CubeCOS 是什麼?
CubeCOS 是由台灣新創公司 Bigstack(堆疊股份有限公司) 自主研發的軟體定義資料中心(SDDC)平台。它結合了私有雲的安全掌控力與公有雲的多元功能,並以「可無縫擴展至整個資料中心」為核心設計理念。目前最新版本為 CubeCOS 3.1。
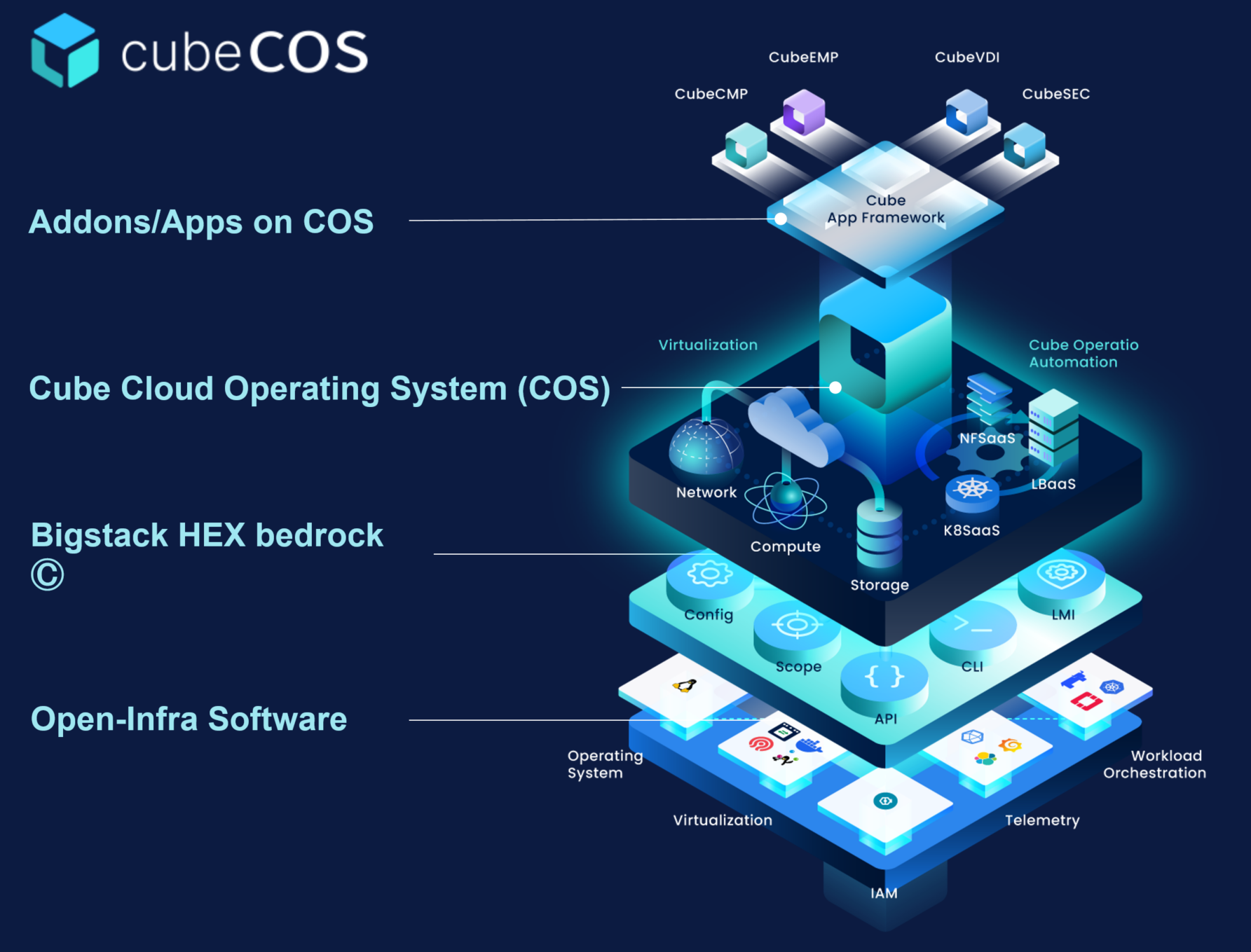
CubeCOS 的四大應用場景
大規模私有雲
部署功能完整、企業級的私有雲環境,兼具公有雲的彈性,並由機構完全自主掌控。特別適合醫院、政府機關等對資料主權要求嚴格的單位。
資料中心建置
透過智能編排、基於政策的自動化及統一管理工具,實現大規模運維簡化,降低維運人力成本。
AI 與機器學習加速工作負載
CubeCOS 透過自動化 GPU 調度、支援多 GPU 叢集,並在虛擬機器與容器上執行工作負載,實現高吞吐量的 AI、機器學習及數據分析工作負載。
彈性橫向擴展
CubeCOS 叢集支援橫向擴展(Scale-Out),無需停機即可新增節點,確保業務持續不中斷。
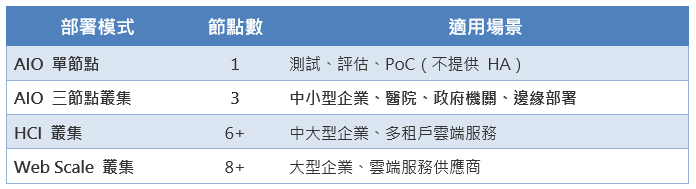
AIO 三節點叢集:最適合醫院規模的部署模式
CubeCOS 支援三種部署架構,醫療機構導入案多採用 AIO(All In One)三節點叢集模式:

儲存架構:Ceph SDS 軟體定義儲存
CubeCOS 採用業界標準的 Ceph 分散式儲存作為後端,提供:
- 分散式、高可用性的儲存後端,單磁碟故障不影響服務。
- 支援 NVMe、SAS SSD、SATA SSD 等多種儲存介質。
- 混合儲存部署模式:高速 SSD 作快取層,大容量磁碟作儲存層,建議 SSD 與 HDD 原始容量比例維持 1:10。
- 每個儲存裝置建議預留至少 4GB RAM 作為 Ceph OSD 記憶體快取,確保儲存效能。
網路設計:流量分離確保叢集健康
CubeCOS 官方建議針對生產環境將網路流量分離,搭配 TOR 交換器(2 台 HA 配置)實現以下流量分段:

各節點建議配置 25GbE SFP28 雙埠 NIC,符合 CubeCOS 官方文件對 SSD/NVMe 儲存環境的最低 25GbE 網路速率要求,確保 Ceph 複製作業不成為效能瓶頸。
算力設計的關鍵考量
1. 異質 GPU 分工,最大化資源效益
GPU 選型可依工作負載特性進行差異化配置。以 H200 NVL 搭配 RTX PRO 6000 Blackwell 的異質組合為例:前者擁有 141GB HBM3e 高頻寬記憶體,適合承載顯存需求大的 LLM 推論或訓練任務;後者以 96GB GDDR7 搭配 PCIe Gen5 介面,提供出色的多工並發能力,適合同時服務多個輕中型推論請求。
CubeCOS 透過高度自動化的設計,讓用戶只需幾次點擊,即可完成從硬體資源分配到軟體環境建置的複雜流程,大幅降低 IT 部門的管理負擔。其 GPU 自動化調度機制 能夠依任務需求,智慧路由至最合適的節點。無論客戶採用何種 GPU 組合,皆可透過統一資源池進行集中管理與分配,避免高價 GPU 被輕量任務佔用,確保算力資源發揮最大效益。
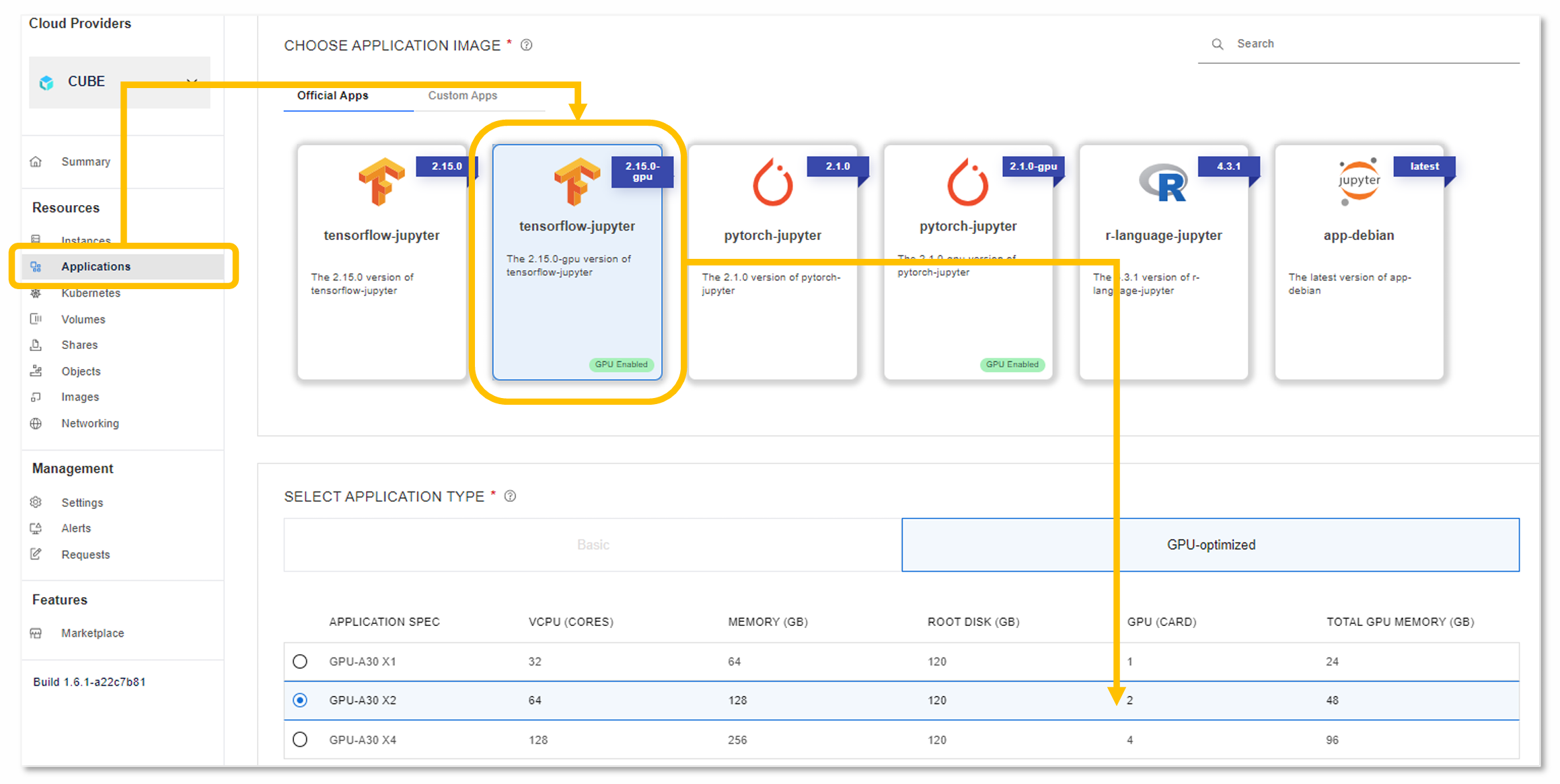
2. GPU 規格彈性選配,精準符合預算與需求
不同規模的客戶對 GPU 算力的需求差異甚大。國眾電腦提供以下幾種典型選配方向供參考:

GPU 型號、每節點數量、節點總數均可依實際需求調整,國眾電腦技術團隊可協助進行工作負載分析與選型建議。
3. 精算電力,確保機房安全上線
算力密度愈高,電力規劃就愈關鍵。以 H200 NVL × 1 加上 RTX PRO 6000 × 4(分布於兩節點)的典型三節點配置為例,全場峰值功耗約 6,210W,其中 GPU 子系統即佔整體功耗逾 48%。
每台伺服器均建議配置 HPE 1800W–2200W Flex Slot Titanium × 4,採 N+1 備援,PSU 負載率控制在 40% 以內,留有充裕熱備份空間。
4. 分散式儲存容錯,資料不遺失
Ceph 分散式儲存的跨節點資料複製機制,確保任一節點或磁碟故障時資料完整保全。驗收測試可模擬拔除單顆硬碟,驗證系統正常運作且資料無遺失。
GPU 算力導入的通用建議
無論是醫療、政府或企業客戶,導入 GPU 算力虛擬化平台前,建議掌握以下要點:
- 先做工作負載盤點,再決定 GPU 型號:推論、訓練、多工並發三種場景對 GPU 顯存與運算吞吐量的需求差異極大,型號選錯會造成資源浪費或效能不足。
- 異質 GPU 組合往往優於單一型號全配:以高顯存卡處理 LLM、以多卡並發處理推論,可在相同預算下達到更高整體利用率。
- 電力與散熱先行:GPU 伺服器功耗密度是一般伺服器的 3–5 倍,機房配電與散熱改造成本不可忽略,且 GPU 規格升級時需重新核算。
- 選擇具 vGPU 調度與 SDS 能力的 HCI 平台:裸機 GPU 無法彈性分時共享,Ceph 分散式儲存確保資料高可用。
- 網路分離是基本功:管理、儲存、服務三層流量分離,才能讓 25GbE 的頻寬用在刀口上。
- HA 功能需明確驗收:CubeCOS 的 HA 保護層面與 VMware vSphere HA 有所不同,應於驗收階段針對實際環境逐項測試確認。